
Interaction Design, Information Architecture, Machine Learning
Duration: Oct 2018 – Dec 2018, 2 months
My Role: UX Designer
Tools: Sketch
IBM AutoAI

Project Overview
Auto AI (formerly AutoML) is an automated machine feature in IBM’s Watson Studio designed to simplify Machine Learning by automating the end-to-end process, thereby saving time, money, and resources. It is designed for citizen users, or beginner users, who may not have the domain knowledge for traditional machine learning.
This was a 2-month internship.

The UX Design Team
Alex Swain – Design Principal
Nicole Black– UX Designer
Kristina Davis – UX Designer
Lisa Lessenger – UX Designer
Problem
Currently, the user experience for AutoAI is a black box and lacks a source of truth for data.
There is no indication of what goes on during training. After training, it gives pipelines an “excellent” or “poor” rating but never indicates why or how the data received that rating. If there is an error during the process, never indicates what went wrong.
These issues make the experience difficult for the user, which defeats the purpose of automating the system.
Solution
In order to improve the user’s experience, we needed to offer:
A transparent training process that gives the user a clear explanation of what is happening to the data and how the model is built.
The ability to backtrack in the process.
Leave room for future expansion or additional features.
Research + Domain Knowledge
Before designing, our team needed a crash course in ML and data science to know at least the basic process to understand what features were required
What is ML?
Machine Learning (ML) explores the study and building of algorithms that can learn and make predictions on data without being explicitly programmed to do so.
Instead, ML relies on patterns through sample data. ML is commonly used in predicting sales trends, weather forecasts, or email filtering.
Traditional ML vs. AutoML
Traditionally, Machine Learning is resource-intensive and requires significant domain knowledge and time to produce and compare dozens of models. Below is an abridged process of standard machine learning.

AutoML, on the other hand, allows for faster creation of models that often outperform traditional handmade models by automating almost the entire process. Data is automatically scaled or normalized to help algorithms perform well.

Competitor Analysis
One of the first tasks that we tackled was to research different AutoML competitors. We took note of what each competitor did well and what they lacked. Researching competitors also gave us an idea of how AutoML worked as a whole. The strengths and weaknesses of each competitor were based on customer reviews from Trust Radius and Gartner.




As-is & to-be process
After initial research, the team mapped out what the current process of AutoML was. See the problems. Then, we developed an ideal process of what features needed to be there and any future elements to include later.


Iterations
With this in mind, the team developed different iterations on the user flow. This was a learning process. Over time, we learned what could and couldn’t be done, what the software limitations were, and any coding limitations. Below are few of the many iterations we designed over the course of two months.





Mid-Fidelities
Two months later, we had an MVP that gave the basic process, along with the ability to add additional features later on. Our basic process included:
Setting up the data to train.
The training itself.
Post-training & Compare Mode.
Set-up
Training setup is a three-step process. First, the user would upload or select an existing data set, then choose a column to predict, and finally, choose a metric to optimize. The user can also select columns to ignore during the training process, which could decrease the time it takes for the data to train.

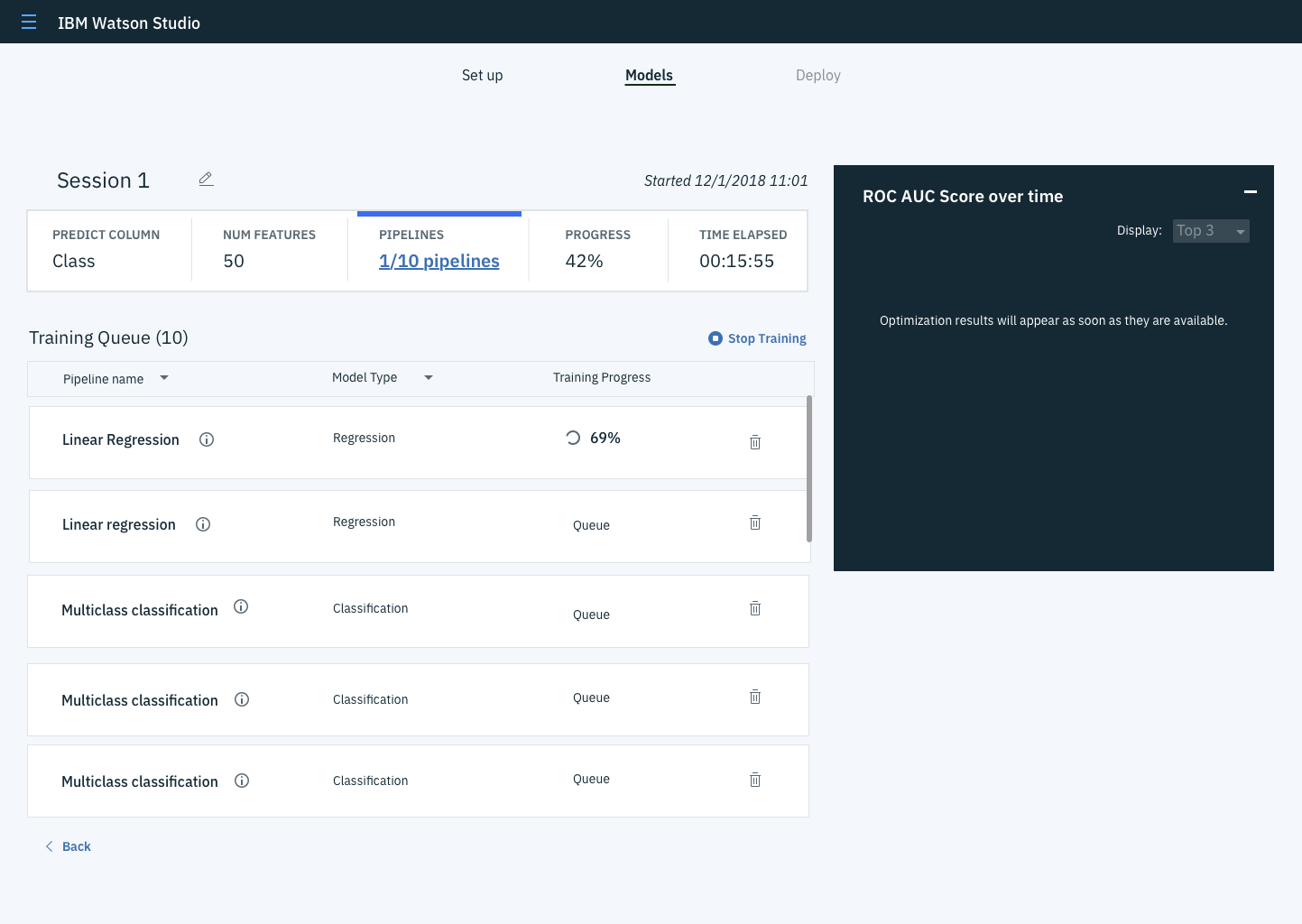
Training Data
As training progresses, each pipeline would show up in the left margin.

Compare Mode
Compare mode gives the ability to compare the different pipelines so the user can choose the one that best fits their needs.

View Model Details
The user can view detailed information on an individual pipeline.

Takeaways
UX is different from Graphic Design.
A real world job is different from academia.
Scope creep is a thing.